PyTorchのLSTMを使った自然言語分類器の要素開発
以下のリポジトリの説明です。新規性は何も無いと思いますが、強いて言うならWeb I/Fとシームレスに繋げるのは少し頑張りました。
目次
プロジェクト構成
python-chatbot
├─chatbot … Djangoプロジェクトの総親モジュール
│ asgi.py
│ settings.py
│ urls.py
│ wsgi.py
├─aicore … AI演算用のコアモジュール。演算コアのみの実装であり、制御部はstoreifに統合。
│ botcore.py
│ common.py
│ network.py
├─api … REST API提供用のDjangoアプリケーション
│ admin.py
│ apps.py
│ models.py
│ serializer.py
│ tests.py
│ urls.py
│ views.py
└─storeif … データモデルを扱うI/F実装のためのDjangoアプリケーション。Frontend UI、AIスレッドもこちらに実装。
│ admin.py
│ apps.py
│ models.py
│ tests.py
│ views.py
└─management
└─commands
runai.py
システムモデル
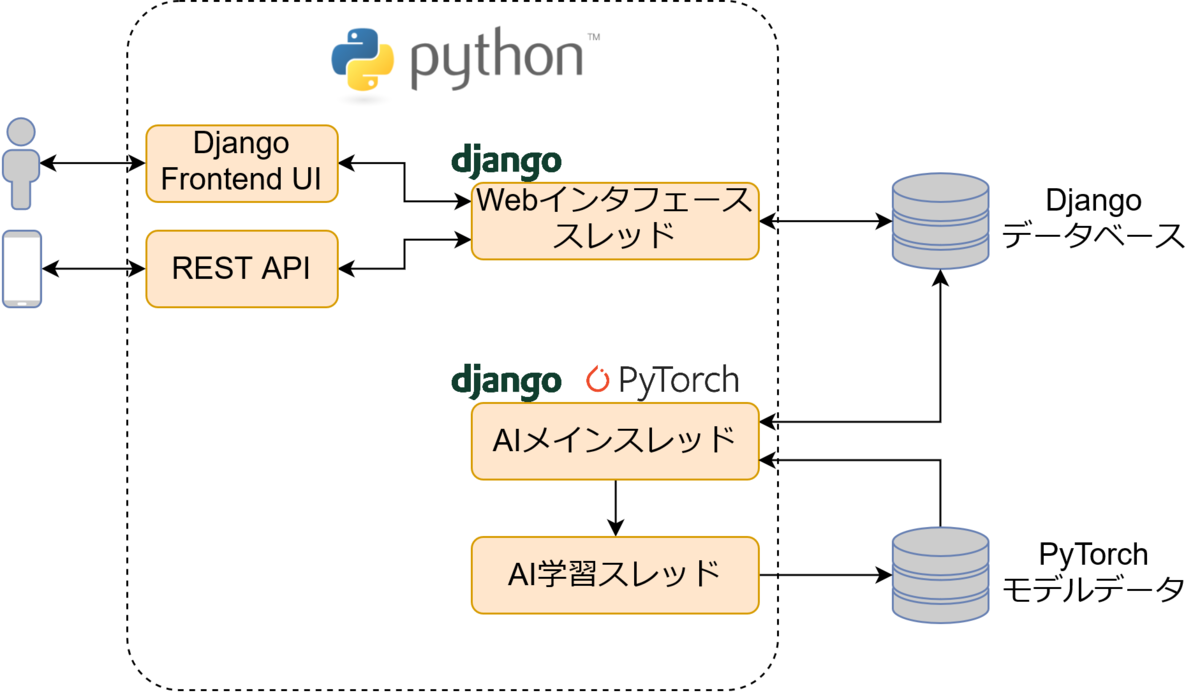
- Webインタフェーススレッド
Djangoのメインスレッド。runserverで動くDjangoプロジェクト本体のようなものです。- Django Frontend UI
ユーザからの操作を受け付けるGUIです。Djangoのテンプレートエンジンのみで作成。
storeif · release/0.1.0 · Yoshiyuki Harada / python-chatbot · GitLab - REST API
Django REST frameworkを使用したREST API。学習データの投入や学習器の学習開始などを実装。
API使用側は何も作ってないです。(図のスマホは飾りです)
api · release/0.1.0 · Yoshiyuki Harada / python-chatbot · GitLab
- Django Frontend UI
- AIメインスレッド
PyTorchのモデルを保持して要求を待ち受けるやつ。実装全体は以下のファイル。
storeif/management/commands/runai.py · release/0.1.0 · Yoshiyuki Harada / python-chatbot · GitLab - AI学習スレッド
AIメインスレッドで使用しているモデルを学習させるためのスレッドです。
処理時間がかかるので非同期処理ためにマルチスレッドアーキテクチャとする。
storeif/management/commands/runai.py · release/0.1.0 · Yoshiyuki Harada / python-chatbot · GitLab
学習器の概要
今回作成した学習器は文章を入力として、その文章が属する分類(クラス)を推測する多クラスの分類問題を解くものです。
前処理にはMeCabとWord2vecの組み合わせを使用し、ニューラルネットワークには2層のLSTMと2層のパーセプトロンからなる層数4層のネットワークモデルを作成しました。 Word2vecの学習済み辞書にはデフォルトで東北大学の鈴木先生の日本語Wikipediaエンティティベクトルをダウンロードして使用しています。*1
概要は下図のとおりとなります。この例では2クラスに分類する場合ですが、クラス数が増えた場合も出力の最後の次元が増える以外は同じです。

学習器の設計思想
今回の学習器の思想は次のような感じです。数理的な考察は一切できていません。改善の余地しか無いと思うので色々お教えいただけるとありがたいです。
- 1層目のLSTMで単語の次元圧縮(200→50)を行います。対象となるドメインに不要な特徴量を削ぎ落とそうとしています。
- 2層目のLSTMは同じく特徴の圧縮(50→20)を行いつつ、特徴量を伝搬させながら最後のセルに伝達して文全体の特徴を抽出しています。 なんとなくここの出力次元数を小さくしすぎている気がします。数倍必要かもしれません。
- 2層のパーセプトロンはあんまり深く考えずに突っ込みました。得られた特徴をクラス数まで圧縮する仕事をしてもらっています。 LSTM層で圧縮しすぎると時間軸方向の特徴伝搬にしくじる気がしたので別途圧縮していますが、正直2層は要らないと思います。「深層」って言いたかったので入れた以上の理由は無いです。
所感
PyTorchを初めて使ってみました。Chainerの思想をほぼそのまま引き継いでおり、Chainerユーザーにとっては学習コストの殆どかからない嬉しいフレームワークになっていると思います。
一箇所引っかかったところとしては、調子に乗ってマルチスレッドでメモリ上に展開したモデルを共有してたらGPU化したところで怒られました。当たり前っちゃ当たり前ですね。
*1:CC BY-SA
